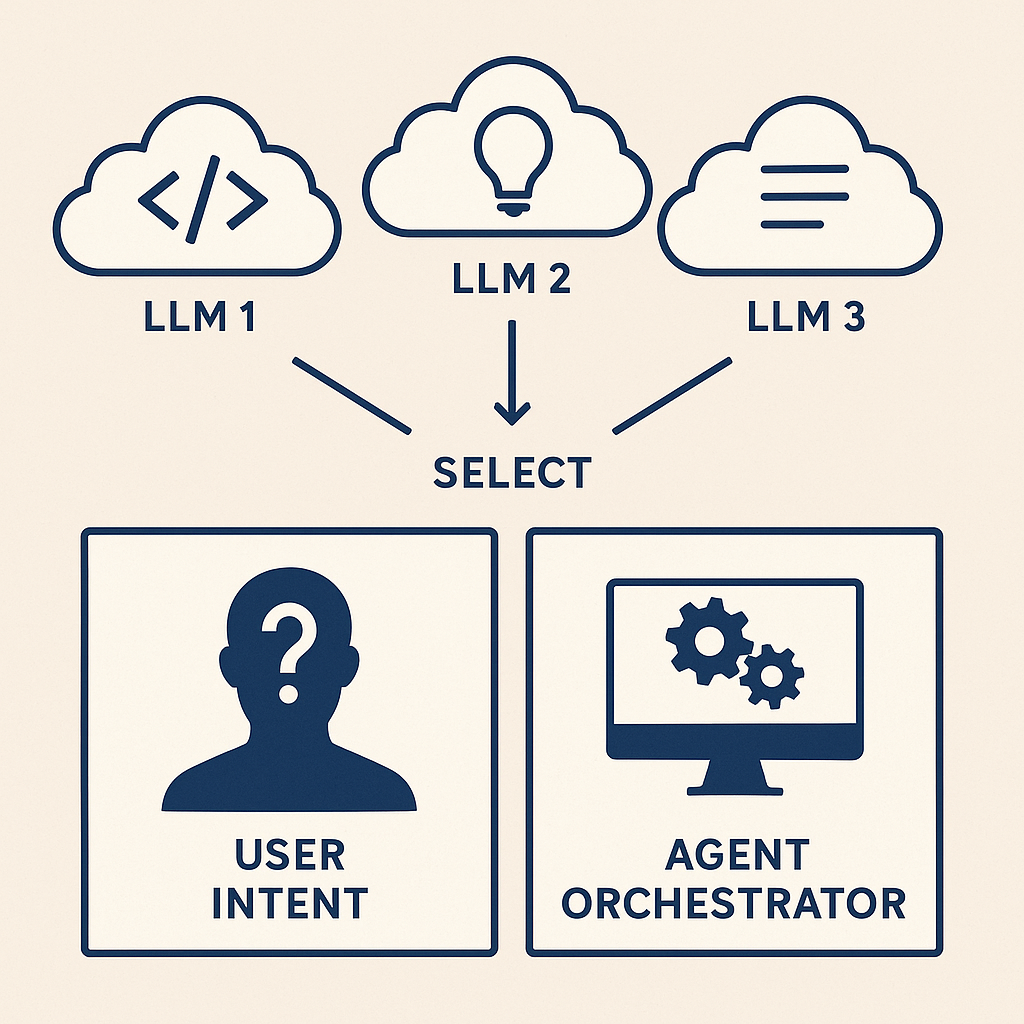
The nBrain Approach to Intelligent Model Orchestration
The debate over "which LLM is best" is the wrong question. Just like you wouldn't ask which tool in a toolbox is best, you shouldn't rely on a single AI model. Here's how we build intelligent infrastructure that uses them all.
"The discussion around which LLM model is best is a meaningless discussion. It would be like arguing what the best tool in your toolbox is. They all have reasons to be part of your AI infrastructure. Some are better at coding, some are better at creative work. Some are cheaper, faster, and some have higher/lower token limits. To get the most out of AI, you need to use all of them."
"The good news: when you control what you are doing with AI privately, you don't need to make the decision. We take it another level and let our Agent orchestrator decide. AI knows which tool to pick for the job."
Relying on a single AI model is like trying to build a house with only a hammer. Each model has unique strengths and weaknesses that make it ideal for specific tasks.
No single model excels at everything. GPT-4 might be versatile, but Claude outperforms it in complex reasoning and code generation, while Gemini handles longer contexts better.
Using premium models for simple tasks is like hiring a neurosurgeon to put on a bandaid. You're overpaying for capabilities you don't need for that specific job.
Powerful models are slower and more expensive. Simple queries don't need the most advanced model, but choosing the wrong one manually for each task is impractical.
Committing to a single provider puts you at their mercy for pricing, availability, and feature releases. True control requires flexibility.
Different models have different context windows. A 200K token model is overkill for a simple question, but essential for analyzing long documents.
Vision tasks need vision models. Code generation needs code-optimized models. Creative writing benefits from different models than data analysis.
Just like a carpenter needs different tools for different jobs, a robust AI infrastructure needs different models for different tasks.
Excels at complex reasoning, nuanced understanding, and detailed code generation with strong safety guardrails.
The versatile generalist with strong performance across diverse tasks, extensive plugin ecosystem, and proven reliability.
Handles extremely long contexts (up to 2M tokens), excellent for document analysis, research, and multimodal tasks.
Open-source powerhouse enabling private deployment, full customization, and zero API costs at scale.
Efficient European model with strong performance-to-cost ratio, excellent for high-volume production workloads.
Vision models (GPT-4V, Claude Vision), code models (Codex), embedding models (ada-002), and task-specific fine-tuned models.
At the heart of nBrain's infrastructure is an intelligent orchestrator that analyzes each request and routes it to the optimal model. Here's how it works under the hood.
"Analyze this 50-page contract and summarize the key terms"
Analyzes complexity, context length, task type, and performance requirements
Long Document + Legal Analysis + High Accuracy Required
Routes to Gemini 1.5 Pro (2M token context window)
Attaches document parsing + summarization tools
Processes request, returns formatted summary with citations
// Simplified orchestrator logic
async processQuery(userQuery) {
// Step 1: Analyze the request
const analysis = await this.analyzeQuery(userQuery);
// Step 2: Classify task requirements
const requirements = {
complexity: analysis.complexity, // simple | medium | complex
contextLength: analysis.tokenCount, // in tokens
taskType: analysis.category, // code | creative | analysis | etc.
speedPriority: analysis.urgency, // low | medium | high
accuracyNeeds: analysis.criticalness // standard | high | critical
};
// Step 3: Select optimal model
const model = await this.selectModel(requirements);
// Step 4: Route and execute
const response = await model.execute(userQuery, {
tools: this.getRelevantTools(requirements),
temperature: this.getOptimalTemperature(requirements),
maxTokens: this.calculateMaxTokens(requirements)
});
return response;
}Every query flows through a sophisticated analysis pipeline that ensures the right model handles each task.
The orchestrator first analyzes the incoming request to understand what's being asked and what resources will be needed.
Based on the analysis, the system maps out what characteristics the ideal model should have for this specific request.
The orchestrator evaluates all available models against the requirements and selects the optimal one for this specific task.
The system identifies and prepares the tools, functions, and integrations the model will need to complete the task.
The request is executed with real-time monitoring to ensure quality, catch errors, and optimize performance.
Every interaction feeds back into the system, continuously improving model selection accuracy and performance.
See how the orchestrator makes intelligent decisions for different types of requests.
| User Request | Model Selected | Reasoning |
|---|---|---|
| "What's the weather like?" | Llama 3.1 (70B) | Simple query, no complex reasoning needed. Fast local model saves costs and provides instant response. |
| "Debug this React component and explain the issue" | Claude Sonnet 4 | Complex code analysis requiring deep reasoning and detailed explanation. Claude excels at code review. |
| "Analyze this 200-page market research PDF" | Gemini 1.5 Pro | Massive context window needed (2M tokens). Gemini handles long documents without truncation. |
| "Write a creative story about a space explorer" | GPT-4 Turbo | Creative writing task where GPT-4's training on diverse creative content shines. |
| "What's in this image?" | GPT-4 Vision | Vision task requires multimodal model. GPT-4V provides detailed image analysis. |
| "Analyze Q3 financials and predict Q4 trends" | Claude 3 Opus | Complex analysis requiring reasoning over structured data, trend identification, and forecasting. |
| "Summarize today's emails" (100+ emails) | Gemini 1.5 Flash | High-volume processing needing long context. Flash variant optimizes for speed and cost. |
| "Generate SQL to find inactive customers" | Claude Sonnet 4 | Precise code generation with business logic understanding. Claude's reasoning ensures accurate SQL. |
User: "Help me create a marketing campaign for our new product launch"
Orchestrator Decision: Multi-model approach
Result: Each model contributes its strength, creating a comprehensive campaign faster and better than any single model could alone.
Building with intelligent orchestration delivers compounding benefits across performance, cost, reliability, and innovation.
Every task gets handled by the model that's best at that specific job, ensuring consistently high-quality results.
Automatically route simple queries to cheaper models and complex ones to premium models. Typically saves 70-90% on AI costs.
If one model is down or rate-limited, the orchestrator seamlessly fails over to an alternative. No single point of failure.
Route sensitive data to self-hosted models while using cloud models for non-sensitive tasks. Full data sovereignty.
New models come out constantly. Add them to the pool and let the orchestrator evaluate when to use them. No architecture changes needed.
The system learns from every interaction, getting smarter about which models work best for which tasks over time.
Access vision, code generation, embeddings, and other specialized models exactly when needed without managing multiple interfaces.
Your business logic stays independent of any single provider. Switch models, add providers, or negotiate better terms anytime.
Test new models on a subset of traffic, A/B test different approaches, and optimize based on real performance data.
Want to build this yourself? Here's the step-by-step path to creating your own intelligent model orchestration system.
Traditional Development: Building this infrastructure from scratch typically takes 6-12 months with a team of 3-5 experienced AI engineers, costing $300K-$600K.
The nBrain Approach: We've built, tested, and optimized this infrastructure so you don't have to. Our platform gives you production-ready multi-modal orchestration in days, not months.
Key Technical Stack: Node.js/Python backend, PostgreSQL + Pinecone for storage, React frontend, Docker for containerization, LangChain/LlamaIndex for orchestration frameworks, and monitoring via Prometheus/Grafana.
The companies winning with AI aren't asking "which model should we use?" They're building infrastructure that uses the right model for each job, automatically.
Think of it like electricity. You don't ask "should I use coal or solar power?" You flip a switch and the grid intelligently sources power from whatever makes sense at that moment. Your AI infrastructure should work the same way.
When you control your AI infrastructure privately with intelligent orchestration, you get:
This isn't theoretical. This is how nBrain's platform works today, handling thousands of queries daily with intelligent orchestration that continuously learns and improves.
The debate over "the best AI model" is over. The answer is: all of them, used intelligently.
Whether you want to build it yourself using our roadmap or deploy nBrain's battle-tested platform, we're here to help you harness the full power of AI.
Or reach out to discuss your specific needs: hello@nbrain.ai